Catalyst Blog
Featured Post

For the Enterprise, Coding Co-pilots Are Simply Not Enough
The hype around one specific part of next generation software…
SEARCH & FILTER
More From The Blog
Search for
Category
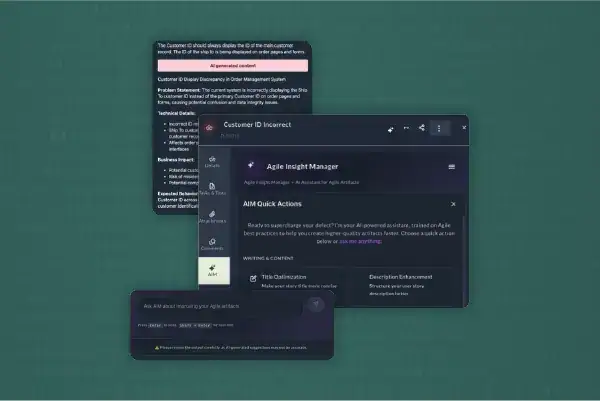
The Real ROI of AI Starts Inside the Workflow
Productivity gains help individuals. Agentic AI is what strengthens alignment,…

Dopamine & Dopamine-RootHide: The Myth of the Undetectable Jailbreak
Recent jailbreak releases such as Dopamine 2.4.x and its fork…

How Conflicting Security Directives Can Leave You Without Any Oxygen
If HAL-9000 Didn’t Read Lips, Dave Bowman Wouldn’t Have Had…

Securing AI-Generated Code with Digital.ai Release
Introduction: AI Code Security and Its Emerging Risks Large Language…

Why Your Security Stack is Like Baking Cookies at 10,000 Feet (And How to Stop Them From Falling Flat)
Last weekend, I spent three hours trying to bake the…

The Return to Bare Metal: Why We’re Done Pretending
For the better part of two decades, we’ve been sold…

How Common Is Code Obfuscation in Popular Android Apps?
Whether the goal is to steal intellectual property, gain access…

Deliver with Evidence: Safer Orchestration, Smarter Rollouts, and Scalable Processes (Release 25.3)
According to recent surveys, 31% of DevOps leaders said a…

The Fourth Wave is Already Here: What 18 Years of Agile Data Tells Us About What’s Next
For nearly two decades, Digital.ai’s State of Agile Report has…



