Published: January 15, 2020
Web and Mobile Testing: How to Locate Elements
When it comes to automating web and mobile testing the main idea is to simulate real user actions to cover all possible use cases. This is mainly used for regression testing purposes. This way you build confidence in the process of introducing new functionality or bug fixes. The main goal is to not break anything that already works. Second and no less important is that the end-user experience remains smooth and issue-free.
The industry’s most popular tools for cross-browser and cross-platform web and mobile automation are Selenium and Appium correspondingly. This article covers the main strategies for locating application controls (buttons, links, images, text, etc.) so you will be able to identify the right way of identifying the elements to interact with.
First of all, what is an Element? In the UI test automation world it is the smallest unit of a web or mobile application which can be interacted with (clicked, hovered, receive keyboard or mouse or tap events). For images and text fields you might want to check the presence/absence of the element or test the application layout. So the Element is basically a HTML or XML element, normally it is a HTML or XML tag.
So given the following code snippet: <a id=“foo” href=“https://experitest.com”>Experitest</a>
- a is the HTML tag representing a hyperlink
- @id and @href are HTML attributes and “foo” and “https://experitest.com” are their respective values
- Experitest is the hyperlink text
Now let’s see how we can “find” this link to be able to work with it (click or verify its attributes or text values).
If you look into oorg.openqa.selenium.By class JavaDoc, you will see that there are several strategies for locating the Elements in the application under test. Here are the main 3:
- Id
- CssSelector
- XPath
The other remaining strategies are:
- Name
- ClassName
- LinkText
- PartialLinkText
- TagName
These are self-explanatory therefore don’t require any further description.
So out of these 3: Id, CSS, and XPath, which one to choose? The order the strategies are listed in is chosen intentionally because:
- Id – is the fastest way of locating the element and its footprint in terms of resources is minimal
- CSS – slower and more resource consuming option of locating the element, but it gives more flexibility
- XPath – the slowest and the most “expensive” of them, however, it’s the most powerful option as XPath is almost a programming language
Getting Element Details from Web Page or Mobile Application
Looking into the page source
Both Selenium and Appium WebDriver implementations provide getPageSource() function which returns the underlying HTML or XML layout of the current web or application page. You can save the output of this function into a file and then open the file using your favorite browser and use its developer tools to inspect the elements and identify “interesting” attributes.

Using browser developer tools on the webpage
The majority of modern browsers come with developer tools that can be used for getting extended information regarding page source, looking for specific elements, web and mobile testing selectors, debugging scripts, etc. Normally developer tools can be opened using the F12 button. If you cannot – refer to your browser documentation.

Using Appium Inspector Session
If you run the Appium Desktop application it is possible to kick off an Inspector Session where you will be able to see the page source and element properties.

Here is what it looks like for iOS:

And here is the Android equivalent:

Finding Web and Mobile Testing Elements by ID
Given that the element, you need to work with has a unique ID attribute the most straightforward way of locating it is by sticking to this ID. Just make sure that:
- There are no other elements with this ID as if they are, Selenium and/or Appium will work with the first element they will find and it will not necessarily be the one, you’re looking for the ID looks more or less human-readable. For example <input id=“password”/> seems to be an identifier which is not likely to be changed, and is <input id=“id_j116”/>. Suspicious as it might be automatically generated and may be a subject to change on next application build/deploy or even on page reload
ID-based selectors are very easy to develop, in case of
- Web applications – the id attribute of the relevant HTML element
- Android applications – a resource-id attribute of the relevant XML element
- iOS applications -a named attribute of the relevant XML element
If your application elements don’t have IDs – the best option would be talking to your application developers and asking them to introduce unique identifiers for each element where possible. It might be also required for analytics. For example, user activity tracking so most probably they will agree.
CSS Selectors
In a case where element IDs cannot be used, you can still locate the element using CSS selectors. It is slower than ID and consumes more resources in terms of CPU and RAM, however, you will have way more options to match the element you’re looking for.
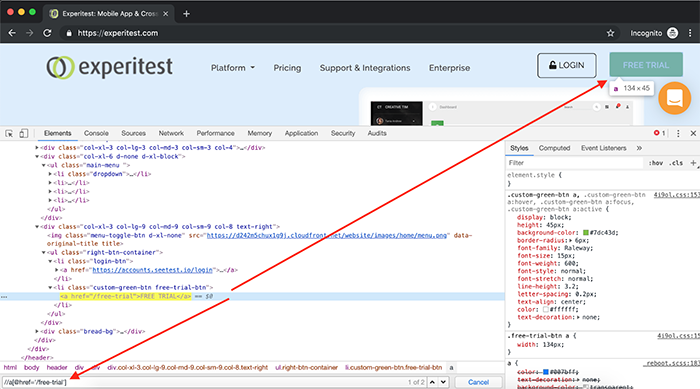
For example, the FREE TRIAL button at https://experitest.com/ page looks like:
FREE TRIAL
as you can see there is no ID attribute, however, you can use the href attribute value to locate the element, the relevant CSS selector would be:
a[href=”/free-trial”]

You can even do a partial match like a[href*=”trial”] and still locate the element.
XPath Selectors
In a situation when you neither have a unique ID nor can go for a CSS Selector you will have to consider XPath. Although it’s the slowest and the most resource-consuming option, it’s the most powerful one. It has full access to DOM you can use XPath Axes for accessing elements parents, children, siblings, whatever, combine several expressions, use existing XPath Operators and Functions for exact matching and even create new ones if the existing cannot be used for your scenario.
For simple queries like the aforementioned FREE TRIAL link the syntax is pretty much similar to CSS, the same element locator to match the href attribute in XPath language will be:
//a[@href=’/free-trial’]
Some more XPath selectors to match the same element:
- Find a link with FREE TRIAL text: //a[text()=’FREE TRIAL’]
- Find a link which contains FREE text: //a[contains(text(), ‘FREE’)]
- Find a link which starts with FREE text: //a[starts-with(text(),’FREE’)]
- And a bonus. There is no ends-with() function in XPath 1.0, however you can come up with the equivalent using existing functions. Find a link which ends with TRIAL text: //a[substring(text(), string-length(text()) – string-length(‘TRIAL’)+ 1, string-length(text()))= ‘TRIAL’]
If you face difficulties in coming up with an XPath expression don’t forget Appium Studio. It provides a simple and easy visual way to manage devices/emulators, provisioning profiles, test code generation via recording, and Object Spy can generate unique XPath expression for an element at the page so you can create a locator in one click.

Now you should have a clear understanding regarding which element selectors to use, the pros, cons, capabilities, and limitations of each of them. Hopefully, this information will make your lives easier and your web and mobile testing more robust and reliable.
You Might Also Like

iOS Test Recorder: A Faster Way to Turn Validation into Automation
We listened to your feedback. The iOS Test Recorder is…

Start Testing Samsung Galaxy S26 Series Today with Digital.ai Testing
Samsung has officially introduced the Galaxy S26 series, continuing its lineup…

Android 17 Beta Support Now Available with Digital.ai Testing
As we move closer to the anticipated release of Android 17 —…